
Extra-Wide Covering Indexes
 2
2
- Details
SQL Server indexes are constrained to a maximum width of 900 bytes. In this video you'll learn how to get around that limit using T-SQL in order to create indexes that can be used for a wide variety of performance purposes - including 'extra wide' covering indexes.
This Video Covers
Indexes, the SQL Server Storage Engine, and T-SQL tips and tricks.
Details
Video Length: 07:55
Skill Level: 400 - Guru
Series: Tips and Tricks
Author/Presenter: Michael K. Campbell
Applies to SQL Server: 2000, 2005, and 2008
Tags: Tips and Tricks, Indexing, T-SQL, and Storage Engine
- Downloads

+ Related Videos
Nibbling Deletes

Learn how to execute large numbers of deletes from large tables without negatively impacting concurrent write operations.
Covers: The SQL Server Storage Engine, and T-SQL tips and tricks.
Skill Level: 300 - Advanced
Video Length: 09:19
Release Date: 2008-09-24
Ad-hoc Reporting
Learn how to easily export Query results to non-technical users using the tools you already have.
Covers: Reporting, Query Output, Query Analyzer, and SQL Server Management Studio.
Skill Level: 100 - Beginner
Video Length: 08:27
Release Date: 2007-03-10
Using SQL Server Templates
In this video you'll learn how to use, create, and manage SQL Server Templates.
Covers: Code Reuse, T-SQL, SSMS, Query Analyzer, and Code Management.
Skill Level: 200 - Intermediate
Video Length: 07:09
Release Date: 2008-10-08
How to use SQLServerVideos.com
Want the inside scoop on how to use SQLServerVideos.com? Check out this short video to make the most of your visits to the site.
Covers: How to use SQLServerVideos.com and associated resources.
Skill Level: 000 - Overview
Video Length: 05:19
Release Date: 2008-07-18
+ Related Resources
Inside Microsoft SQL Server 2005: Query Tuning and Optimization

Pages 118-121 & 214 provide information about the benefits of covering indexes - including some of the improved benefits offered by SQL Server 2005's INCLUDE statement. Pages 121-124 also provide great information on bookmark lookups as well.
Microsoft SQL Server 2000 Optimization Guide

Page 197 calls out some of the trade-offs involved in creating covering indexes - and also lists some best practices for their deployment.
SQL Server Pro
Aviv's full article in the Reader to Reader section of the magazine can be found here. (And make sure to check out the comments for additional information.)
SQL Server Books Online
Here are some relevant links from Books Online that correspond to content covered in this video:
CREATE INDEX ( 2000 2005 2008 (Pending) )
Index with Included Columns
BINARY_CHECKSUM ( 2000 2005 2008 (Pending) )
SQL Server Central
This great blog post by Ken Kaufman provides a great overview of covering indexes in general and calls out some of their trade-offs as well as some of the improved benefits of creating covering indexes with SQL Server 2005's INCLUDE statement.
+ Transcript
NOTE: Accompanying timeline provides approximate correspondance only.
00:00
-
-
-
-
00:15
-
-
-
-
00:30
-
-
-
-
00:45
-
-
-
-
01:00
-
-
-
-
01:15
-
-
-
-
01:30
-
-
-
-
01:45
-
-
-
-
02:00
-
-
-
-
02:15
-
-
-
-
02:30
-
-
-
-
02:45
-
-
-
-
03:00
-
-
-
-
03:15
-
-
-
-
03:30
-
-
-
-
03:45
-
-
-
-
04:00
-
-
-
-
04:15
-
-
-
-
04:30
-
-
-
-
04:45
-
-
-
-
05:00
-
-
-
-
05:15
-
-
-
-
05:30
-
-
-
-
05:45
-
-
-
-
06:00
-
-
-
-
06:15
-
-
-
-
06:30
-
-
-
-
06:45
-
-
-
-
07:00
-
-
-
-
07:15
-
-
-
-
07:30
-
-
-
-
07:45
-
-
-
-
07:55
TODO: Synchronize transcript with playback...
SQL Server indexes are constrained to a maximum width of 900 bytes.
In the Reader-to-Reader section of the November 2007 issue of SQL Server Magazine, Aviv Zucker provided an example of a creative way to ensure unique values in columns wider than 900 bytes wide by using a rarely-used T-SQL function and a unique index.
Therefore, in this video, which is largely based on his idea, we’ll go ahead and take a brief look at Aviv’s sample solution, then look at a couple of ways to extend his idea in order to provide other indexing solutions as well.
To get started, we’ll quickly create the definition for a new table that contains a primary key, a couple of fairly narrow columns, a few wider columns that are less than the 900 byte limit for indexes, along with 2 columns that exceed the 900 byte limit.
Then, using Red-Gate’s SQL Data Generator, I’ll go ahead and spam twenty-two thousand and… eighty-seven rows into our sample table.
And, in one of the wider columns, I’ll constrain data to be unique, while in other columns we’ll just allow, or assign, random values without worrying whether those values are unique or not.
Then with those settings in place, I’ll go ahead and click on the Generate Data button to fire off the generation process – and load our sample table with a bunch of bogus data.
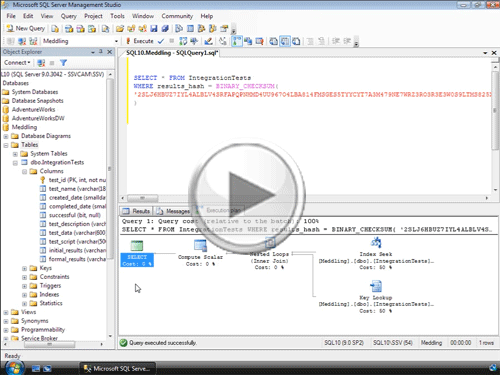
With our table now populated with data, if I try to create an index on that wide column, I’ll get an error, 1946 – telling me that the column I’ve attempted to index is too wide. Which is where Aviv’s great idea comes into play.
And to see how his idea works, watch what happens when I run a query using the T-SQL BINARY_CHECKSUM function.
As you can see, this barely used function – designed to help detect row-changes – provides us with a powerful way to get an integer hash of our existing data.
Using this approach, we can create a computed column – with the BINARY_CHECKSUM data as the value. And, with that column added, we can then impose a unique index, or constraint, on our ‘hash’ column – which will effectively impose the same constraint on our wider column.
And it was this exact approach that Aviv detailed in order to allow him to enforce unique constraints across columns wider than 900 bytes.
To test this out, we can simply SELECT a few rows, copy and paste the value from one of the rows into an UPDATE statement, and then try to fire that off – only to be greeted by an error telling us that the attempted UPDATE violates our UNIQUE index.
Pretty ingenious, right?
Now, while Aviv’s approach to ensuring uniqueness has some great merit in a number of cases, we can also build off of his ingenious approach to derive other benefits as well.
For example, let’s do a SELECT against this same table to grab the row matching the exact text that I just copied and pasted.
If we execute this query and look at the execution plan, we see that we’re doing a clustered index scan – and that’s typically all we could ever hope for with a column that exceeds the 900 byte limit.
However, if we tweak our query just a bit to make it SARGable – by seeking against the matching BINARY_CHECKSUM of the data we’re looking for, we can re-execute the query and check the Execution plan to see that we are, indeed, executing an index seek – which makes the query drastically cheaper.
Obviously, we lose the ability to scan WITHIN our index, but if that were our intent we’d likely also lose seek performance anyhow as our query would no longer be SARGable. But with this approach, we’re way better off than we would be in many cases.
What’s great though is that if you’re purposefully attempting to seek against columns that are wider than 900 bytes wide, the cost to create these indexes, using BINARY_CHECKSUM, is really quite minimal as the entire indexed domain is only an integer, or 4 bytes, wide.
And, even better: if you intend to expose this kind of seek-ability to end-users or applications, you can easily create a stored procedure that transparently wraps this functionality with a tiny bit of redirection that can help take advantage of ‘extra wide’ index capabilities.
By the same token, if we look at two of our other columns: test_data and test_script, they’re both under 900 bytes each, but together – they’re over 900 bytes wide, meaning that they can’t be used to create a composite index.
Or course, using the same BINARY_CHECKSUM hashing approach, we can also create what is known as a hash index against both of these columns in order to perform equality searches. Obviously, such an approach would come with some limitations, but could also be a life-saver in a number of use-cases – especially since it imposes VERY little overhead.
In a very similar manner, it’s also possible for us to create covering indexes using this same ‘extra wide’ approach.
For example, let’s go execute that sproc that we just created, and check out the execution plan – where we see that in order to execute correctly we’re actually incurring an index seek, accompanied by a bookmark lookup.
The overall approach is still drastically cheaper than an index scan, and on this really small table, the extra performance ‘hit’ is barely measurable. But on a much larger table this bookmark lookup could add significant overhead.
As such, we can also use covering indexes in conjunction with this hashing approach. Obviously, this only works if you’re 100% seeking against the entire indexed value, but in cases where it does, you’re really only indexing a single integer, along with any other data that you want ‘piggy-backed’ on to your covering index – which can make this a wicked-fast option that imposes very little overhead in the right scenarios.
To see how well it performs, we just need to re-execute our sproc, and take a look at the execution plan – where we see that performance has been drastically decreased through a vastly simpler execution plan.
Better yet, since everything we’ve looked at so far works in SQL Server 2000 and up, if you’re using SQL Server 2005 or 2008 you can create better covering indexes with one of my all-time favorite additions to SQL Server 2005: the INCLUDE clause.
With this approach, you’re able to explicitly create a covering index using the INCLUDE statement to achieve similar READ performance, along with significantly improved performance when it comes to index maintenance or writes.
Where things can get really cool with SQL Server 2005 though, is in cases where you also want to pull back ‘wide’ columns as part of your result set.
With SQL Server 2000, you’d have to resort to a bookmark operation to pull back this other ‘extra-wide’ column, but with the INCLUDE statement you can include it as part of your covering index.
Now, if we add these changes, and re-execute our sproc, we see that we’re returning that additional column, but if we switch to the Execution Plan tab, we can see that we’re still pulling back all of these results using an Index Seek – which results in excellent performance.
And, as you’ve seen, we’ve been able to index ‘wide data’ while also being able to return it – allowing, if you will, for the creation and use of extra-wide covering indexes.
And with that, we’re done with this Video. I’m Michael Campbell and I hope you’ve enjoyed this SQL Server Video – and I hope to see you in subsequent videos.
- Comments
Do Not Redistribute
Please do not redistribute this content.
+ I Already Agreed - Stop Bugging Me
Non-Registered users must agree not to distribute each new time that they visit the site (prior to the first download per each visit or session on the site).
Registered users don't have to agree to terms each time they visit the site.
Registration costs nothing, is painless, and is evil-free™. And SQLServerVideos.com will never divulge your personal information to third parties. Ever.
Registered Users
Login Here
+ Terms of Service
By using this site and its resources, you agree to the following terms of use:
Redistribution is prohibited.
Redistribution of videos via any of the following means is prohibited:
• WebServer/HTTP, FTP
• YouTube and similar sites,
• BitTorrent and other P2P technologies,
• CD/DVD, Portable Hard-Drive, etc.
All Rights Reserved.
• SQLServerVideos' Parent Company, OverAchiever Productions, reserves all intellectual rights associated with this site and its content.
• OverAchiever Production reserves the right to prosecute or litigate copyright violations.
• As the copyright owner, OverAchiever Productions will also request information (from Google, YouTube, etc.) about anyone that posts copyrighted SSV
content to a video distribution site.
Creating unique indexes on checksum columns is a bit "dangerous". It is possible that two different values can produce the same hashed value, and the unique index will give an error when it shouldn't
what a clean explanation.. keep it up..
Add A Comment